一、文心一言大模型的构成
文心一言大模型是基于深度学习技术构建的,其核心是一个巨大的神经网络。这个网络经过了大量的训练,通过观察海量的文本数据学习了语言的规律和语义信息。模型的构成主要包括以下几个组成部分:
- 神经网络架构:文心一言采用了深度神经网络的架构,通常是由多层神经元组成的深度结构。这种结构能够更好地捕捉语言的复杂特征和关联关系。
- 预训练模型:文心一言大模型是基于预训练的方式构建的。在正式使用之前,模型经历了大规模的预训练,通过这一过程,模型能够理解语言的基本规律和语义信息。
- 参数与权重:模型中的每一个神经元都有对应的参数和权重,这些参数和权重是通过训练数据优化得到的。它们决定了模型对输入数据的处理方式和输出结果。
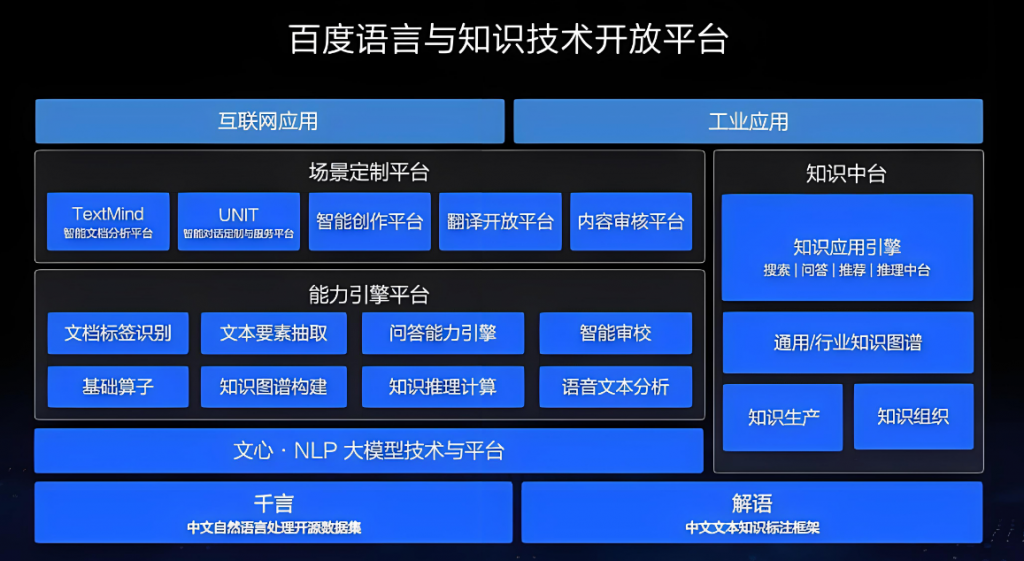
二、NLP模型的特点及优势
NLP模型具有以下几个显著的特点和优势:
- 语义理解能力强:NLP模型通过大规模的预训练和微调,具备了强大的语义理解能力,能够准确理解文本的含义和语境。
- 多领域适用:NLP模型可以应用于各个领域,包括医疗、金融、教育等,满足不同领域的语言处理需求。
- 自动化处理:NLP模型能够实现自动化处理,提高工作效率,节省人力物力成本。
- 个性化定制:NLP模型可以根据用户的需求进行个性化定制,为用户提供更加精准的服务和推荐。
- 持续学习进化:NLP模型具有持续学习和进化的能力,通过不断的更新和优化,提升模型的性能和效果。
三、文心一言的执行流程
当用户向文心一言提出一个问题时,整个执行流程可以简单地分为以下几个步骤:
- 接收问题:首先,文心一言接收用户提出的问题。这个问题可以是任何形式的自然语言文本,比如一句话、一个段落或者一个问题描述。
- 文本处理:接下来,模型会对接收到的文本进行处理。这个步骤包括分词、词性标注、实体识别等自然语言处理技术,目的是将文本转换成计算机能够理解和处理的形式。
- 特征提取:在理解了用户的问题之后,模型会提取问题中的关键特征。这些特征可能包括问题的主题、关键词、语义信息等,用于后续的处理和分析。
- 模型推理:接下来,文心一言会将提取到的特征输入到预训练的神经网络模型中进行推理。模型会根据输入的特征,利用之前学习到的知识和规律,生成与问题相关的回答或者解决方案。
- 输出结果:最后,文心一言将生成的结果返回给用户。这个结果可能是一段文字、一张图片、一个建议或者一个解决方案,取决于用户提出的问题和模型的输出能力。
通过以上执行流程,文心一言能够高效地处理用户提出的问题,并给出相应的回答或解决方案。这种基于深度学习的自然语言处理技术已经在各种应用场景中得到了广泛的应用,为用户提供了更加智能和便捷的服务。