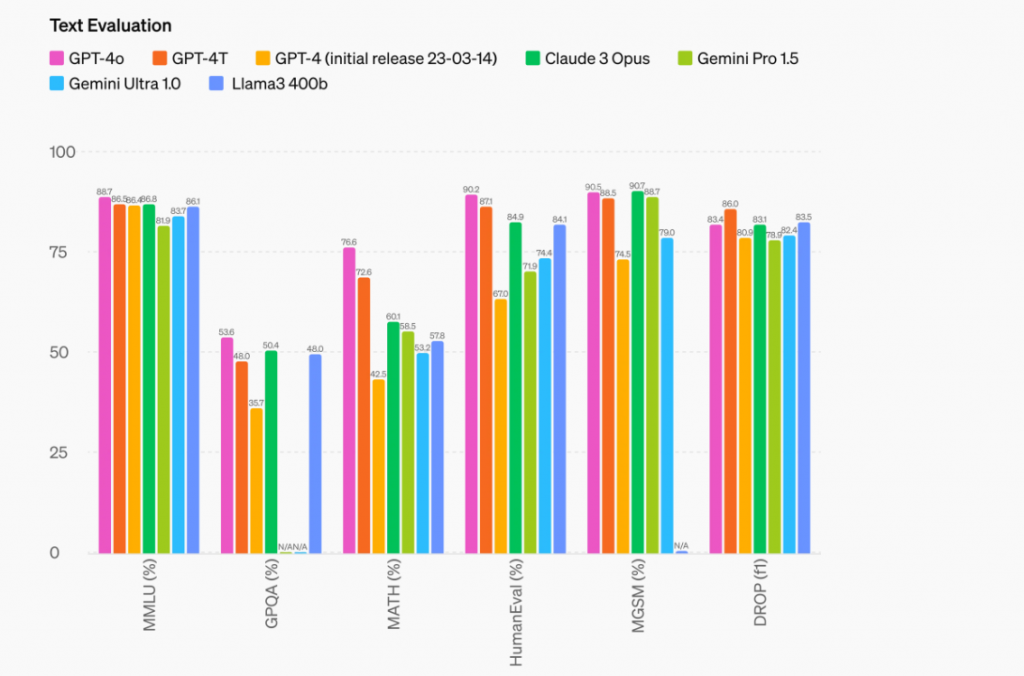
GPT-4o是OpenAI推出的最新旗舰模型,能够实时处理文本、音频和图像输入输出,显著提升了多模态交互体验。其性能在多语言、音频和视觉理解方面有显著改进,响应速度更快,API成本降低50%。模型在文本推理和编码上与GPT-4 Turbo相当,但在非英语语言处理上表现更佳。此外,GPT-4o在安全性设计上也进行了优化,包含多项新安全措施和评估系统。

如需代注册GPT帐号、代充值 GPT4.0会员(plus)及充值API,请添加站长微信(wsxx1415)
GPT-4o(”o”代表“omni”)是向更自然的人机交互迈出的一步——它接受任意组合的文本、音频和图像输入,并生成任意组合的文本、音频和图像输出。它能在232毫秒内响应音频输入,平均响应时间为320毫秒,这与人类对话反应时间相似。在英文文本和代码上,它与GPT-4 Turbo表现一致,但在非英文文本上有显著改进,同时速度更快,API成本降低了50%。GPT-4o在视觉和音频理解方面优于现有模型。
OpenAI首席执行官奥尔特曼表示,GPT-4o的语音功能让人想起了电影《她》,“感觉就像是电影中的人工智能,我仍然对其感到惊讶。”
据美国《华尔街日报》13日报道,OpenAI首席技术官米拉·穆拉蒂(Mira Murati)在发布会上表示,GPT-4o的速度比现有的GPT-4 Turbo快了两倍,但成本仅为其一半。GPT-4o可以实时对文本、音频和图像进行推理,响应时间几乎达到人类水平。
GPT-4o 是推动深度学习边界方面的最新一步,这次着重于实用性。过去两年中,每一层技术堆栈上进行了大量的效率改进。作为这一研究的首个成果,能够更广泛地提供与 GPT-4 级别相当的模型。GPT-4o 的功能将逐步推出。
GPT-4o 的文本和图像功能今天开始在 ChatGPT 中推出。我们在免费层次中提供 GPT-4o,并为 Plus 用户提供高达 5 倍的消息限制。几周内,我们将在 ChatGPT Plus 中以 alpha 版本推出 GPT-4o 的新语音模式。
开发者现在也可以在 API 中访问作为文本和视觉模型的 GPT-4o。GPT-4o 比 GPT-4 Turbo 快 2 倍,价格降低一半,速率限制提高 5 倍。我们计划在未来几周内向一小部分受信任的合作伙伴推出 GPT-4o 的新音频和视频功能支持。
图片生成更快、更准确,生成图片相比GPT-4响应时间提升明显。
